前言
在多线程编程之中,通常我们最常需要考虑的是两个问题:1. 竞争问题;2. 协调问题。
竞争问题是指多个线程对同一个资源的竞争,比如:需要修改同一个变量、写同一个文件或者修改数据库的同一条记录……
对于竞争问题,我们通常通过锁机制来保证同一个资源每次只能被一个线程访问。
至于协调问题,一般又分为两种:1. 协调多个线程执行的操作的顺序;2. 多个线程间信息的传递
事实上,问题1往往也是通过问题2来解决的,比如:
一个线程继续向下执行的条件是判断某个变量是否为
true而另一个线程中,将该变量的值设为
true实际上,就是一个线程通过共享变量,向另一个线程传递了信息,从而控制了其执行的行为
因此,协调问题,最终又可归结为多线程间信息的传递。
Java中,多线程间的信息传递是靠共享变量实现的。而 JMM(Java Memory Model / java内存模型) 可以说是Java提供的一系列准则和规范,旨在帮助程序猿们准确、高效地解决多线程编程中的协调问题(在JMM中称之为同步问题 Synchronzation)。
我们在很多文章、很多地方听到的许多很难望文生义的名词(诸如:顺序一致性、happens-before原则、内存可见性、MESI等),都来自于JMM。甚至于JMM本身,从其字面意义就很难理解这到底是个什么玩意儿。
JMM究竟是什么?
我们现在说的JMM一般指从JDK5开始使用的新内存模型,详细描述可以查阅JSR-133(注:JSR - Java Specification Requests/ Java 规范提案)
Oracle官方文档《Java Language Specification》第17章 Threads and Locks,第4小节 Memory Model 中也有收录。
其开头就有这么一段话:
The memory model describes possible behaviors of a program. An implementation is free to produce any code it likes, as long as all resulting executions of a program produce a result that can be predicted by the memory model.
大概意思是:JMM可以描述一段程序可能的行为。多线程编程中,如果我们按照JMM的规则写程序,即我们写的程序可以由JMM规则预测出确定的结果,那么我们就可以放飞自我、为所欲为了(不用担心产生无法预期的bug)。
不由让我想到了一句话:We are free, in the cage. 只要咱按照JMM给的规矩写程序,咱就是自由的。
同时,我又想吐槽了,一个指导我们怎么program的规则,干嘛叫Memory Model,为啥不叫Program Model?
为何需要JMM?
为何需要JMM,实际上等价于:为什么多线程编程很容易出bug?为什么不按照JMM编程,就容易产生预期之外的结果?
还是举前言里面的例子,就这么简单的逻辑,能出啥错?
还就真能出错,虽然一个线程将共享变量的值设为了true,但另一个线程可能要等1分钟、10分钟甚至更久才能察觉到这个共享变量的值变为了true,这显然并非我们预期的结果。
为啥会出错?
因为cpu最终执行的指令并非我们原本写的程序,这其中经过了编译器的优化重排序、cpu的指令重排序以及cpu缓存导致的内存重排序,这些各式各样的优化目的是让程序运行的更快,更有效率,但是却可能导致多线程的程序执行结果无法预期。
可能我们还有个问题,JMM只和多线程编程有关?如果只用一个线程,就不需要关心JMM了吗?
答案是肯定的,单线程不需要考虑JMM。原因在于,上面所说的导致程序运行结果无法预期的各种重排序优化,都必须要遵循 as-if-serial 语义,即无论怎么重排序,单线程程序的执行结果不能被改变。
JMM如何指导我们进行多线程编程?
JMM对本地内存的抽象
首先我们需要明确几个定义:
- 共享变量(Shared Variables):JMM将所有存储在堆内存中的变量(包含了对象实例、静态变量和数组元素)称之为共享变量。因为这些变量存储在堆中,所以被所有线程共享,也是线程间消息传递的媒介。
- 本地内存(Local Memory):本地内存是JMM抽象出的一个概念,并不是真实存在的,也就是说无论我们去查JVM的运行时数据区、Object内存布局还是其他什么,都找不到本地内存这么一个东西。这是JMM为了向程序员屏蔽JVM下层的各种优化,而虚拟出来的一个概念。
也就是说,在理解多线程的程序如何运行时,我们不用去管编译器、操作系统、处理器这些底层优化机制,我们只需要想象,共享变量是存储在主存中对所线程共享的,而每个线程都有一个独享的本地内存,本地内存中缓存着共享变量的副本。
如下图所示:
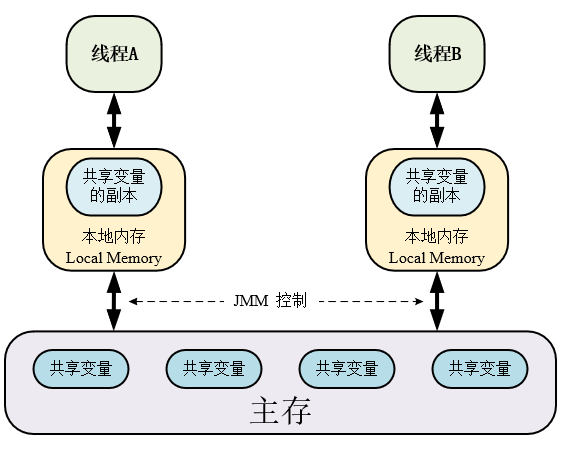
可见,各个线程无法直接读写主存中的共享变量,只能接触到各自本地内存中缓存着的共享变量的副本。至于缓存何时将共享变量改变了的值写回主存中去,缓存何时从主存中读取共享变量最新的值,这就由JMM来规定了。
了解了JMM对本地内存的抽象,我们再来思考一下前言中的例子。
一个线程以为自己将共享变量的值修改为了true,但实际上修改的只是自己本地内存里的副本。
而另一个线程一直在轮询的也不是真正的共享变量的值,而是自己本地内存里副本的值。
因此,前一个线程的共享变量副本写回主存的时机,以及后一个线程共享变量副本从主存中读取最新值的时机,都影响着程序运行的实际行为。
换一种说法,就是前一个线程对共享变量的操作结果对另一个线程来说不可见。
happens-before规则
JMM的核心就是happens-before规则。
happens-before是什么?
如果我们说
操作A happens-before 操作B,那么其含义是:操作A的结果对操作B可见。注:happens-before直译过来是“发生在….之前”,但实际上,仅对于消息传递而言,我们并不是特别关注操作A是不是真的在操作B之前执行,我们关心的是操作B要能立刻看到操作A执行的结果。
那么有哪些happens-before规则呢?
- 一个线程中的每个操作 happens-before 该线程中的任意后续操作。
- 对monitor锁的解锁操作 happens-before 任意后续对该锁的加锁操作。
- 对 volatile 变量的写操作 happens-before 任意后续对该变量的读操作。
- 如果 A happens-before B,B happens-before C,则可以推导出 A happens-before C。
- 一个线程中的任意操作 happens-before 从该线程的 join() 方法返回。
- 调用一个线程的 start() 方法 happens-before 该线程中的任意操作。
- 一个对象的默认值初始化 happens-before 任何后续操作。(注:这里是默认值初始化,而不是构造函数的初始化,也就是说,一个对象new出来之后,可能不一定能立刻读到构造函数中对各个字段的赋值,但至少能读到默认值0、null或false,而不会读到内存中的随机值。)
和程序员密切相关的一般是前4条happens-before规则。
使用happens-before规则
还是举前言中的例子,如何使用 happens-before 规则改进程序呢?
显然第1个规则不适用,因为对共享变量的读和写是在两个线程中的。
第2个似乎可以,在读和写共享变量前后分别加上加锁和解锁操作,于是 加锁 - 修改共享变量 - 解锁 happens-before 加锁 - 读共享变量 - 解锁,这样一个线程就能立刻读到另一个线程修改的结果了。
第3个似乎也可以,对共享变量增加 volatile 关键字,于是 写volatile变量 happens-before 读volatile变量,应该也可以达到我们预期的结果。
坐而论道不若起而行,我们不妨试试。
1 | public class T01_happensBefore { |
上面的代码中,主线程启动了另一个线程,之后就一直检查flag,另一个线程会在2秒后将flag设置为true。
执行结果:
1 | main start |
却迟迟看不到主线程检查到的flag的变化。
我们试试volatile,只需要在flag的声明处加上volatile关键字。
1 | static volatile Boolean flag = false; |
执行结果:
1 | main start |
使用synchronized在flag读写处加锁也是可以达到预期结果的,这里就不再赘述。
volatile
从happens-before规则中我们可以看到,volatile是多线程间协调的重要工具,我们来重点看看volatile的特性。
1 | public class T02_volatile { |
上面的代码中,我们假设线程A中先执行write()方法,之后线程B中执行read() 方法。
按照happens-before规则:
- 根据规则1:1 happens-before 2,3 happens-before 4
- 根据规则3 volatile规则:2 happens-before 3
- 根据规则4 传递性:1 happens-before 4
于是我们发现:一个线程在对 volatile 变量写之前,对其他共享变量的操作,对于另一个线程读 同一个volatile 变量之后,都是可见的。
如果我们以JMM对本地内存的抽象来理解,可以认为:
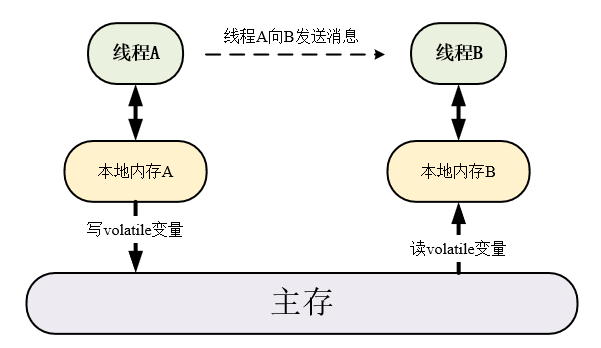
- 对一个 volatile 变量写时, JMM 会把该线程本地内存中对应的共享变量副本值写回到主存中去。
- 对一个 volatile 变量读时, JMM 会把该线程本地内存中对应的共享变量缓冲置为无效,接下来对共享变量的读取会先从主存中读取到最新值。
所以,线程A写一个 volatile 变量,随后线程B读这个 volatile 变量,这个过程实质上是线程A通过主存向线程B发送消息(消息是共享变量(不限于volatile变量)的修改)。