前言
Redis提供的Replication(复制)特性,能够通过很简单的配置,实现Redis服务器的主从复制功能。
不过,通常不会只单独使用Replication,而是会搭配Sentinel(哨兵)实现主备高可用或者搭配Cluster(集群)实现数据分片的高可用集群。
本文仅介绍Replication相关配置和特性。
使用
Replication主要用于解决两个问题:
提高并发响应能力
一个master处理写请求,多个slave分摊读请求的压力。
高可用
如果master挂了,将一个slave选举为新的master,实现故障转移。需要配合Sentinel(哨兵)实现。
开启主从复制非常简单:
在slave的配置文件redis.conf中配置master的ip、端口号和密码即可:
1 | replicaof <masterip> <masterport> |
可以通过INFO replication 命令查看相关信息:
1 | 10.0.0.230:6379> INFO REPLICATION |
Replication常用配置项:
replica-serve-stale-data yes配置为yes,则slave在同步过程中,也会响应客户端请求,配置为no,则在同步完之前会回复SYNC with master in progressreplica-read-only yesslave通常配置为只读模式repl-diskless-sync no若开启,则同步时,master不会先将rdb文件保存到磁盘再传输,而是直接通过网络传输。磁盘性能低但网络带宽大的情况下可以开启。min-replicas-to-write 3如果master连接的slave数量小于3,则master不再接受写请求。这是为了防止出现网络分区后,master和一部分clients被分隔出来,其余的redis实例已经选举产生了新的master并对外服务,如果原master仍然继续可写,那么这些写请求在网络恢复后,实际上就相当于丢失了。min-replicas-max-lag 10如果距离上一次接收到slave的ping的时间超过10秒,即认为该slave不可用。
实现原理
Redis通过重同步(resync)和命令传播(command propagate)来实现不同场景下的数据同步。
重同步
重同步用于将 slave 的数据库状态更新至 master 当前所处的数据库状态。重同步又分为完整重同步和部分重同步。
- 重同步使用SYNC(2.8版本后已被PSYNC取代)或PSYNC命令实现。
- PSYNC可实现完整重同步(
PSYNC ? -1)或部分重同步(PSYNC <replication-id> <offset>) - SYNC只能实现完整重同步
- PSYNC可实现完整重同步(
- 通常初次复制使用完整重同步;断线重连后使用部分重同步
完整重同步
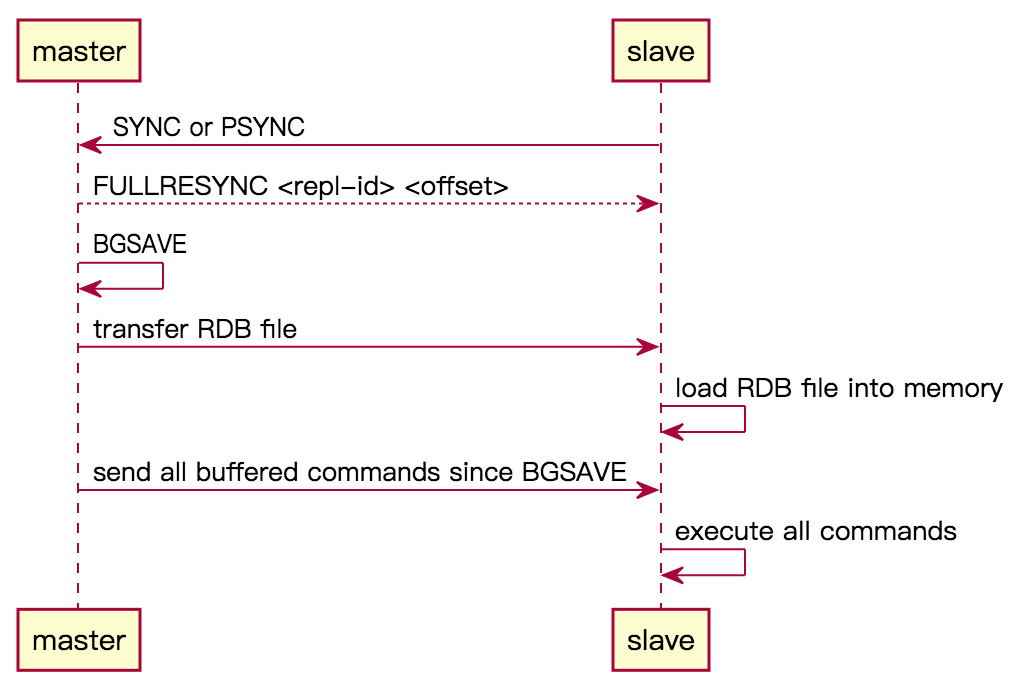
如上图所示,完整重同步流程如下:
- slave 通过 SYNC或 PSYNC 命令,向 master 发起同步请求。
- master 返回 FULLRESYNC 告知 slave 将执行 完整重同步,判定条件为:
- 请求命令是 完整重同步
SYNC。 - 请求命令是 完整重同步
PSYNC ? -1。 - 请求命令是 部分重同步
PSYNC <replication-id> <offset>,但是<replication-id>不是 master 的 replication-id,或者 slave 给的<offset>不在 master 的 复制积压缓冲区 backlog 里面。
- 请求命令是 完整重同步
- master 执行
BGSAVE命令,将当前数据库状态保存为 RDB 文件。 - 生成 RDB 文件完毕后,master 将该文件发送给 slave。
- slave 收到 RDB 文件后,将其加载至内存。
- master 将 backlog 中缓冲的命令发送给 slave(一开始在
BGSAVE时记录了当时的 offset)。 - slave 收到后,逐个执行这些命令。
部分重同步
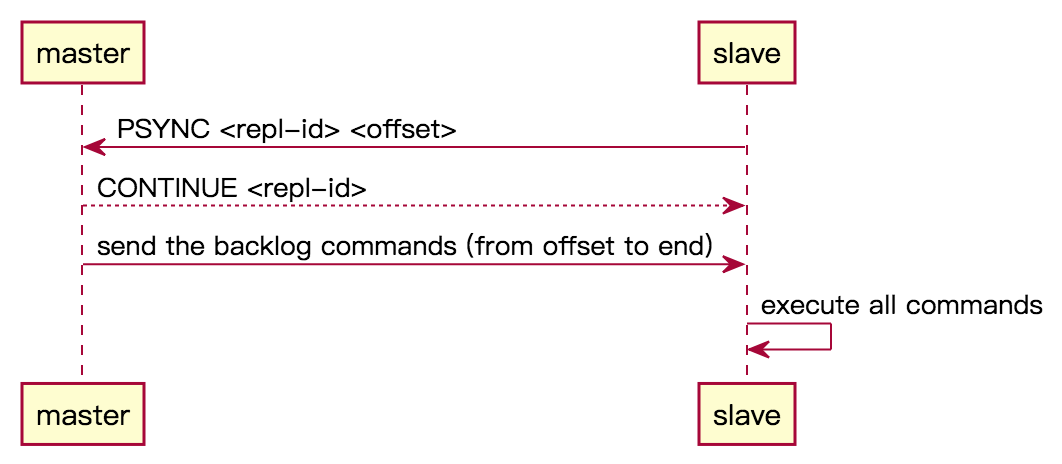
如上图所示,部分重同步流程如下:
- slave 通过
PSYNC <replication-id> <offset>命令,向 master 发起 部分重同步 请求。 - master 返回 CONTINUE 告知 slave 同意执行 部分重同步,先决条件为:
<replication-id>是 master 的 replication-id,并且 slave 给的<offset>在 master 的 复制积压缓冲区backlog 里面
- master 将 backlog 中缓冲的命令发送给 slave(根据 slave 给的 offset)。
- slave 收到后,逐个执行这些命令。
命令传播
命令传播 用于在 master 的数据库状态被修改时,将导致变更的命令传播给 slave,从而让 slave 的数据库状态与 master 保持一致。
master 进行命令传播时,除了将写命令直接发送给所有 slave,还会将这些命令写入 复制积压缓冲区 ,用于后续可能发生的 部分重同步 操作。
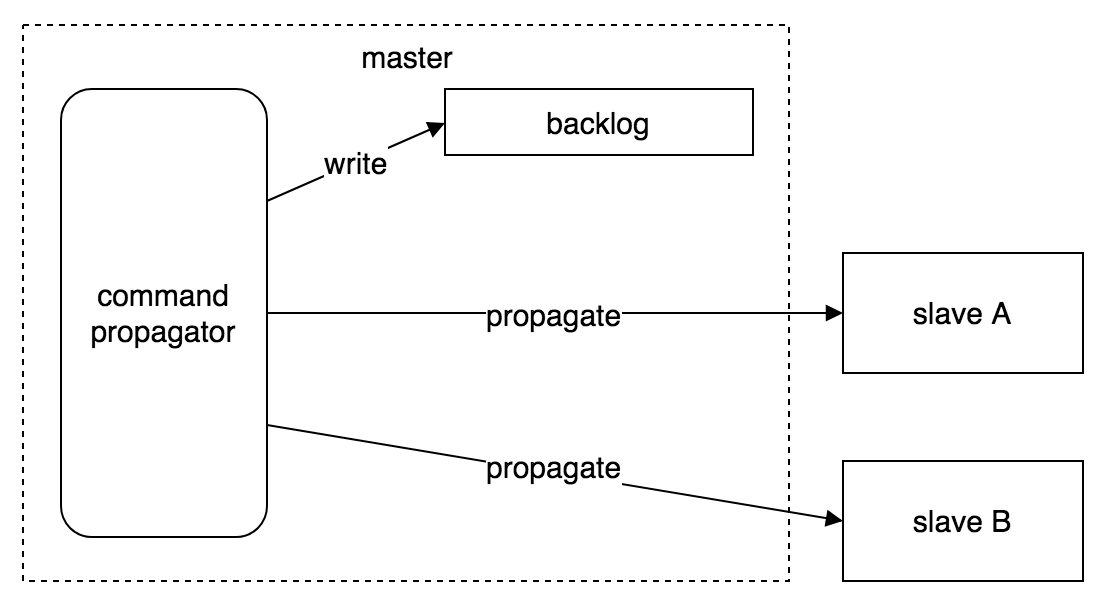
复制积压缓冲区 backlog
复制积压缓冲区 是 master 维护的一个固定长度(fixed-sized)的先进先出(FIFO)的内存队列:
- 队列的大小由配置
repl-backlog-size决定,默认为 1MB。当队列长度超过repl-backlog-size时,最先入队的元素会被弹出,用于腾出空间给新入队的元素。 - 队列的生存时间由配置
repl-backlog-ttl决定,默认为 3600 秒。如果 master 不再有与之相连接的 slave,并且该状态持续时间超过了repl-backlog-ttl,master 就会释放该队列,等到有需要(下次又有 slave 连接进来)的时候再创建。
master 会将最近接收到的写命令保存到 复制积压缓冲区,其中每个字节都会对应记录一个偏移量 offset。
与此同时,slave 会维护一个 offset 值,每次从 master 传播过来的命令,一旦成功执行就会更新该 offset。尝试 部分重同步 的时候,slave 都会带上自己的 offset,master 再判断 offset 偏移量之后的数据是否存在于自己的 复制积压缓冲区 中,以此来决定执行 部分重同步 还是 完整重同步。
弱一致性
默认情况下,Redis使用异步的方式同步数据,即:master不会等待确认slave是否已经同步完成之后,才回复客户端写命令的执行结果。
Redis甚至无法保证最终一致性(最终一致性通常需要消息队列来实现),某些情况下(如故障转移期间),已经确认的写入也是有可能丢失的。
从CAP的角度来说,Redis选择了可用性,而放弃了强一致性。
slave的key过期问题
我们知道对于master的过期key的清理有两种方式:
- 主动判定:周期性随机轮询若干个key,若过期,则清除
- 被动判定:访问某个key时,先判定该key是否过期,若过期,则清除
然而,slave不会主动清除过期的key,只有master判定某个key过期后,主动生成DEL删除命令发送给slave,slave才会清除该key。
这种机制导致了如果master中过期的key没有及时清除,那么从slave中是能够读出的。
从搜索到的很多文章中指出,3.2版本后该问题得到了修复,而Redis官方的Replication文档中指出:对于读取操作,slave会根据自身的逻辑时钟来避免返回一个过期的key。说的比较模棱两可,参考文献[3]中从源码、git的提交记录、实验等多个角度对此问题展开了分析,最终结论是:
- 所谓的逻辑时钟就是系统本地时钟,主从之间并没有针对时钟做同步或相关处理
- 对于expire命令,指定key存活一段时间后过期。即使主从时间不一致,但度过的时长是基本一样的,因此结果通常没有问题。
- 对于expireat命令,指定了key过期的时间戳,这种情况,如果主从时间不一致,客户端在同一时刻访问主从节点的同一个key,得到的TTL是不同的。
因此,建议:
- 运行Redis的机器需要做好对时
- 尽可能使用expire而非expireat
参考文献:
[2] 《Redis设计与实现》